
Ray History Server lets you access the Ray Dashboard and its logs after a Ray cluster has been terminated.
This document describes how to configure and deploy the Ray History Server on Google Kubernetes Engine (GKE) clusters running Ray workloads. This document also explains how to access terminated RayCluster data using a local Ray Dashboard.
By default, the Ray Dashboard and its logs exist only while the Ray cluster is running. When running jobs on ephemeral Ray clusters, the debug data is lost as soon as the cluster terminates. Previously, preserving this data for debugging required keeping idle clusters running, which consumed unnecessary compute resources.
Ray History Server persists this data, which lets you terminate clusters immediately after a job finishes to optimize resource usage. Developers can continue to access the dashboard, review logs, and troubleshoot issues after the compute resources are released.
When configured, Ray History Server acts as the backend for the Ray Dashboard. For more information about using the dashboard, see Ray Dashboard.
Cost
Ray History Server utilizes Cloud Storage. For more information, see Cloud Storage pricing.
Ray History Server container images are stored in Artifact Registry. For more information, see Artifact Registry pricing.
Before you begin
Before you start, make sure that you have performed the following tasks:
- Enable the Google Kubernetes Engine API. Enable Google Kubernetes Engine API
- To use the Google Cloud CLI for this task,
install and then
initialize the
gcloud CLI. If you previously installed the gcloud CLI, get the latest
version by running the
gcloud components updatecommand. Earlier gcloud CLI versions might not support running the commands in this document.
Requirements and limitations
Ray History Server requires a minimum KubeRay version v1.6 and uses Ray version v2.55.
This document assumes that you are familiar with the following concepts and operations:
- Kubernetes concepts and command-line tooling (
kubectl) - Google Cloud projects and command-line tooling (Google Cloud CLI)
- Fundamentals of GKE and Kubernetes
- Fundamentals of Ray and KubeRay
Set up GKE Cluster
In this section, you set up necessary variables and the GKE cluster.
Configure environment variables
The following environmental variables are used throughout this document:
export LOCATION="LOCATION"
export PROJECT_NAME="PROJECT_NAME"
export PROJECT_NUMBER="PROJECT_NUMBER"
export GKE_CLUSTER_NAME="GKE_CLUSTER_NAME"
export GCS_BUCKET="GCS_BUCKET"
export GCP_SA="GCP_SA"
export RAY_JOB="RAY_JOB"
export NAMESPACE="NAMESPACE"
LOCATION: Region or zone of the clusterPROJECT_NAME: Google Cloud project namePROJECT_NUMBER: Google Cloud project numberGKE_CLUSTER_NAME: Name of the GKE clusterGCS_BUCKET: Name of Cloud Storage bucketGCP_SA: Name of the service accountRAY_JOB: Name of the Ray JobNAMESPACE: Namespace where Ray History Server lives in a GKE cluster
Create a GKE cluster
The GKE cluster must have Workload Identity Federation for GKE enabled to access Cloud Storage.
gcloud
Create a Standard cluster with Workload Identity Federation for GKE enabled.
gcloud container clusters create GKE_CLUSTER_NAME \
--location=LOCATION
--workload-pool=PROJECT_NAME.svc.id.goog
Set the kubectl context to the GKE cluster:
gcloud container clusters get-credentials GKE_CLUSTER_NAME \
--location=LOCATION
Configure storage with Workload Identity Federation and service accounts
Set up necessary permissions for Cloud Storage bucket access. For more information, see Workload Identity Federation
Cloud Storage is used to store all the necessary logs and events emitted by Ray and is also used to reconstruct the Ray Dashboard. The Cloud Storage bucket must be created with the setting:
--uniform-bucket-level-access
To create the Kubernetes service account, run the following command:
kubectl apply -f - <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: ray-history-server
namespace: NAMESPACE
automountServiceAccountToken: true
EOF
Bind the roles/storage.objectUser role to the Kubernetes service account:
gcloud storage buckets add-iam-policy-binding gs://GCS_BUCKET \
--member "principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/PROJECT_NAME.svc.id.goog
/subject/ns/NAMESPACE/sa/ray-history-server" --role "roles/storage.objectUser"
Build Ray History Server images
To build the custom image, follow the steps outlined in the KubeRay documentation
Install KubeRay
Add and update the KubeRay repository:
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
helm repo update
To install the KubeRay operator, run the helm install command:
helm install kuberay-operator kuberay/kuberay-operator
Set up Ray History Server
Configure RBAC roles for Ray History Server
Prepare necessary cluster roles and RBAC roles for the Ray History Server components:
kubectl apply -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: raycluster-reader
rules:
- apiGroups: ["ray.io"]
resources: ["rayclusters"]
verbs: ["list", "get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: historyserver
namespace: NAMESPACE
subjects:
- kind: ServiceAccount
name: ray-history-server
namespace: NAMESPACE
roleRef:
kind: ClusterRole
name: raycluster-reader
EOF
Deploy Ray History Server
Create a yaml file HISTORY_SERVER_FILE_NAME with the following manifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: historyserver-demo
labels:
app: historyserver
spec:
replicas: 1
selector:
matchLabels:
app: historyserver
template:
metadata:
labels:
app: historyserver
spec:
serviceAccountName: ray-history-server
containers:
- name: historyserver
env:
- name: GCS_BUCKET
value: "GCS_BUCKET"
image: historyserver:v0.1.0
imagePullPolicy: IfNotPresent
command:
- historyserver
- --runtime-class-name=gcs
- --ray-root-dir=log
ports:
- containerPort: 8080
resources:
limits:
cpu: "500m"
Apply the HISTORY_SERVER_FILE_NAME using kubectl:
kubectl apply -f HISTORY_SERVER_FILE_NAME
Add a service manifest SERVICE_FILE_NAME for Ray History Server:
apiVersion: v1
kind: Service
metadata:
name: historyserver
labels:
app: historyserver
spec:
selector:
app: historyserver
ports:
- protocol: TCP
name: http
port: 30080
targetPort: 8080
type: ClusterIP
Apply the service manifest using kubectl:
kubectl apply -f SERVICE_FILE_NAME
Deploy a Ray Job with an ephemeral Ray Cluster
The collector component of Ray History Server lives on each of the RayCluster Pods and handles collecting the necessary logs and events, and exporting them to Cloud Storage.
Add the following environmental variables required by Ray History Server:
RAY_enable_core_worker_ray_event_to_aggregatorandRAY_DASHBOARD_AGGREGATOR_AGENT_EVENTS_EXPORT_ADDRenable the Ray event export API.RAY_DASHBOARD_AGGREGATOR_AGENT_PUBLISHER_HTTP_ENDPOINT_EXPOSABLE_EVENT_TYPESlists the types of events for the Ray History Server to collect.GCS_BUCKETtells the collector which Cloud Storage bucket to use.
Note: The RayCluster commands are used for setting up Ray History Server and retrieving the node_id as part of the collector container setup. The commands also help ensure that the logs are saved during restart or termination.
- The
rolefield tells the collector which Ray node the collector belongs to. - The
runtime-class-namefield determines the storage client. - The
ray-cluster-namefield defines the name of the RayCluster. - The
ray-rootfield tells Ray History Server the root directory of the logs. - The
events-portfield tells Ray History Server which port the events come from.
The following snippet shows an example RayJob manifest:
apiVersion: ray.io/v1
kind: RayJob
metadata:
name: RAY_JOB
namespace: NAMESPACE
spec:
entrypoint: "python -c 'import ray; ray.init(); print(ray.cluster_resources())'"
shutdownAfterJobFinishes: true
rayClusterSpec:
headGroupSpec:
rayStartParams:
dashboard-host: 0.0.0.0
template:
spec:
serviceAccountName: ray-history-server
containers:
- name: ray-head
image: rayproject/ray:2.53.0
env:
- name: RAY_enable_ray_event
value: "true"
- name: RAY_enable_core_worker_ray_event_to_aggregator
value: "true"
- name: RAY_DASHBOARD_AGGREGATOR_AGENT_EVENTS_EXPORT_ADDR
value: "http://localhost:8084/v1/events"
- name: RAY_DASHBOARD_AGGREGATOR_AGENT_PUBLISHER_HTTP_ENDPOINT_EXPOSABLE_EVENT_TYPES
value: "TASK_DEFINITION_EVENT,TASK_LIFECYCLE_EVENT,ACTOR_TASK_DEFINITION_EVENT,TASK_PROFILE_EVENT,DRIVER_JOB_DEFINITION_EVENT,DRIVER_JOB_LIFECYCLE_EVENT,ACTOR_DEFINITION_EVENT,ACTOR_LIFECYCLE_EVENT,NODE_DEFINITION_EVENT,NODE_LIFECYCLE_EVENT"
command:
- /bin/sh
- -c
- 'echo "=========================================="; [ -d "/tmp/ray/session_latest" ] && dest="/tmp/ray/prev-logs/$(basename $(readlink /tmp/ray/session_latest))/$(cat /tmp/ray/raylet_node_id)" && echo "dst is $dest" && mkdir -p "$dest" && mv /tmp/ray/session_latest/logs "$dest/logs"; echo "========================================="'
# This hook retrieves and persists the node_id for the collector
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -lc
- --
- |
GetNodeId(){
while true;
do
nodeid=$(ps -ef | grep raylet | grep node_id | grep -v grep | grep -oP '(?<=--node_id=)[^ ]*')
if [ -n "$nodeid" ]; then
echo "$(date) raylet started: ${nodeid}" >> /tmp/ray/init.log
echo $nodeid > /tmp/ray/raylet_node_id
break
else
sleep 1
fi
done
}
GetNodeId
volumeMounts:
- name: ray-dir
mountPath: /tmp/ray
- name: collector
image: COLLECTOR_IMAGE
env:
- name: GCS_BUCKET
value: "GCS_BUCKET"
command:
- collector
- --role=Head
- --runtime-class-name=gcs
- --ray-cluster-name=RAY_JOB
- --ray-root-dir=log
- --events-port=8084
volumeMounts:
- name: ray-dir
mountPath: /tmp/ray
volumes:
- name: ray-dir
emptyDir: {}
workerGroupSpecs:
- groupName: cpu
replicas: 1
template:
spec:
serviceAccountName: ray-history-server
containers:
- name: ray-worker
image: rayproject/ray:2.53.0
env:
- name: RAY_enable_ray_event
value: "true"
- name: RAY_enable_core_worker_ray_event_to_aggregator
value: "true"
- name: RAY_DASHBOARD_AGGREGATOR_AGENT_EVENTS_EXPORT_ADDR
value: "http://localhost:8084/v1/events"
- name: RAY_DASHBOARD_AGGREGATOR_AGENT_PUBLISHER_HTTP_ENDPOINT_EXPOSABLE_EVENT_TYPES
value: "TASK_DEFINITION_EVENT,TASK_LIFECYCLE_EVENT,ACTOR_TASK_DEFINITION_EVENT,TASK_PROFILE_EVENT,DRIVER_JOB_DEFINITION_EVENT,DRIVER_JOB_LIFECYCLE_EVENT,ACTOR_DEFINITION_EVENT,ACTOR_LIFECYCLE_EVENT,NODE_DEFINITION_EVENT,NODE_LIFECYCLE_EVENT"
command:
- /bin/sh
- -c
- 'echo "=========================================="; [ -d "/tmp/ray/session_latest" ] && dest="/tmp/ray/prev-logs/$(basename $(readlink /tmp/ray/session_latest))/$(cat /tmp/ray/raylet_node_id)" && echo "dst is $dest" && mkdir -p "$dest" && mv /tmp/ray/session_latest/logs "$dest/logs"; echo "========================================="'
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -lc
- --
- |
GetNodeId(){
while true;
do
nodeid=$(ps -ef | grep raylet | grep node_id | grep -v grep | grep -oP '(?<=--node_id=)[^ ]*')
if [ -n "$nodeid" ]; then
echo $nodeid > /tmp/ray/raylet_node_id
break
else
sleep 1
fi
done
}
GetNodeId
volumeMounts:
- name: ray-dir
mountPath: /tmp/ray
- name: collector
image: COLLECTOR_IMAGE
env:
- name: GCS_BUCKET
value: "GCS_BUCKET"
command:
- collector
- --role=Worker
- --runtime-class-name=gcs
- --ray-cluster-name=RAY_JOB
- --ray-root-dir=log
- --events-port=8084
volumeMounts:
- name: ray-dir
mountPath: /tmp/ray
volumes:
- name: ray-dir
emptyDir: {}
Access terminated RayClusters by using the local Ray Dashboard
Port-forward the historyserver service so that it can be accessed by the local Ray Dashboard:
kubectl port-forward svc/historyserver 8080:30080
Start the local Ray Dashboard
Install Ray locally. Make sure you use the 2.55+ version.
pip uninstall -y ray
pip install -U "ray[default]==2.55.0"
For more information, see Ray releases
the Ray Dashboard, run the ray start command:
ray start --head --num-cpus=1 --proxy-server-url=http://localhost:8080
Start Ray Dashboard on an existing cluster
Alternatively, you can host the Ray Dashboard on the GKE cluster instead of running it locally.
To do this, deploy a Ray cluster with a head-only node that has the proxy server URL field set.
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: raycluster-head-only
spec:
rayVersion: "2.55.0"
headGroupSpec:
rayStartParams:
dashboard-host: 0.0.0.0
num-cpus: "0"
# Pass proxy-server-url to the ray start command to point it to the in-cluster History Server
proxy-server-url: "http://historyserver:30080"
serviceType: ClusterIP
template:
metadata:
labels:
test: raycluster-head-only
spec:
serviceAccountName: ray-history-server
containers:
- name: ray-head
image: rayproject/ray:2.55.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "1"
memory: "2Gi"
requests:
cpu: "100m"
memory: "512Mi"
workerGroupSpecs: []
To access the dashboard the same way as if it were local, port-forward the RayCluster.
This approach allows the dashboard to remain accessible across multiple machines.
kubectl port-forward svc/raycluster-head-only-head-svc 8265:8265
Configure RayCluster for the Ray Dashboard
Finding and selecting the cookies are required for the Ray Dashboard to know which RayCluster to look at.
To select a historical cluster, first get the list of all Ray clusters and their sessions.
In your browser, list your Ray cluster sessions by navigating to the following URL:
http://localhost:8265/clusters
The endpoint call result should look something like the following:
[
{
"name": "ratjob",
"namespace": "default",
"sessionName": "session_2026-03-20_10-50-19_089740_1",
"createTime": "2026-03-20T10:50:19Z",
"createTimeStamp": 1774003819
},
{
"name": "ray-cluster-hs",
"namespace": "default",
"sessionName": "session_2026-03-18_17-11-25_410478_1",
"createTime": "2026-03-18T17:11:25Z",
"createTimeStamp": 1773853885
},
{
"name": "raycluster-historyserver",
"namespace": "default",
"sessionName": "session_2026-02-20_13-03-16_320452_1",
"createTime": "2026-02-20T13:03:16Z",
"createTimeStamp": 1771592596
},
]
Copy a Ray cluster session and navigate to this endpoint in the browser:
http://localhost:8265/enter_cluster/default/raycluster-historyserver/SESSION_ID
The cookies are set when the endpoint loads.
A successful request produces output like the following:
{
"name": "ratjob",
"namespace": "default",
"result": "success",
"session": "session_2026-03-20_10-41-12_950419_1"
}
You can access the log by using the following dashboard endpoint:
http://localhost:8265
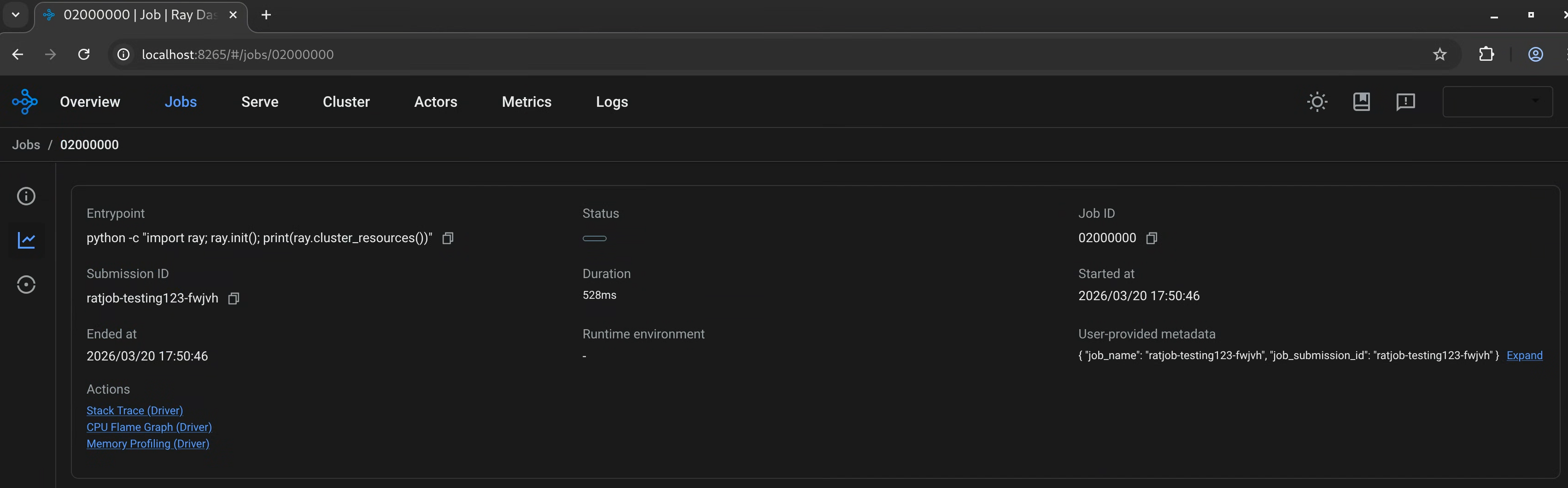
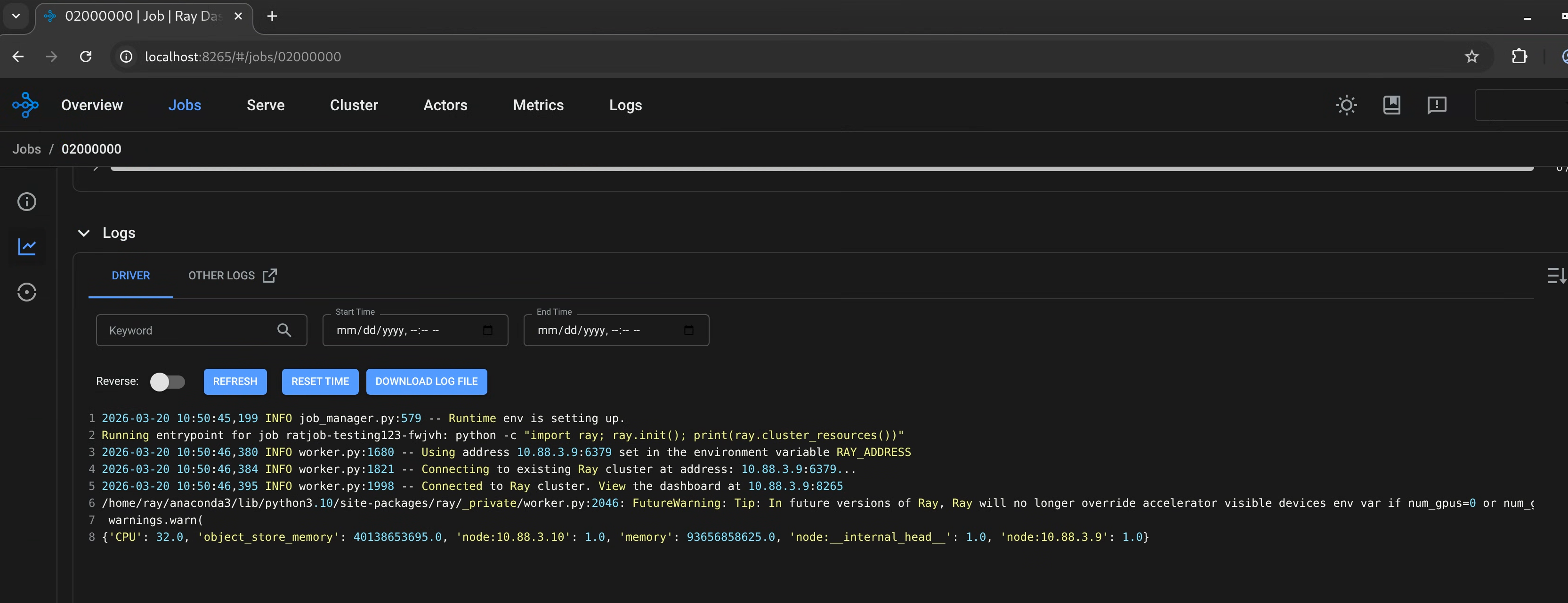
Using the RayJob example, the Ray Dashboard looks like the following examples.
Ray job status page using Ray History Server as a backend:
Ray job log page using Ray History Server as a backend:
What's next
- Send feedback and bug reports to the KubeRay issue tracker in GitHub
- Try running Trillium TPU with Ray
- Learn more about using the Ray operator provided by GKE